Part 1 - Talk to Github Markdowns
OpenAI embeddings, FAISS, Similarity Search, LangChain

Likes Building complex systems with simple architecture and stack. Rust, Golang, C++ and all the Distributed Systems stuff. Had left AI/ML in 2017, thanks to ChatGPT, again clearing desk for Machine Learning projects.
Chatbots have become a popular tool for businesses and individuals looking to improve customer service, automate tasks, and more. These programs are designed to mimic conversation with human users, making them a powerful tool for interacting with customers and clients.
If you're looking to build a chatbot, you might consider using LangChain. LangChain is specifically designed for building chatbots that can interact with users in natural language. In this post, I'll walk you through the process of creating a chatbot using LangChain.
Purpose and Scope of the Chatbot
This post is inspired by ask my book. Instead of taking the book as a source document, we downloaded the Mongodb cloudformation repository and used all the CDK markdown files as the source for answering the questions. The quality of the chat response would depend on the input source document.
Setup
First, let’s get all our imports set up and set an environment variable to contain our OpenAI key export OPENAI_API_KEY=<key> . I have used OpenAI to generate the embeddings as well, which would require a paid account with OpenAI.
from langchain.llms import OpenAI
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.docstore.document import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
from langchain.text_splitter import CharacterTextSplitter
import pathlib
import subprocess
import pickle
Downloading and chunking all the Markdowns
This would process all the markdown files from GitHub. After downloading the files we would also break the text to store it in the form of chunks.
We will use Langchain’s CharacterTextSplitter to preprocess and load our Documents into usable text. Once converted to pages of chunks, it would be easier and more concise to send this information to OpenAI, instead of sending large amounts of irrelevant text.
subprocess.check_call(
f"git clone --depth 1 https://github.com/{repo_owner}/{repo_name}.git .",
cwd=pathlib.Path(dirName),
shell=True,
)
repo_path = pathlib.Path(dirName)
# we are only interested in markdown files for Q&A bot
# skip everything else
markdown_files = list(repo_path.glob("cdk/**/*.md"))
for markdown_file in markdown_files:
print(f"markdown_file : {markdown_file}")
with open(markdown_file, "r") as f:
relative_path = markdown_file.relative_to(repo_path)
github_url = f"https://github.com/{repo_owner}/{repo_name}/tree/master/{relative_path}"
## create in-memory Documents with source and the page content
yield Document(page_content=f.read(), metadata={"source": github_url})
Creating a Vectorised Document Store
For dummies, Vectorizing a text transforms it from strings to an array of numbers. Watch: What is Vectorization?
We have some Vectorize Storage like FAISS, VectorDB to solve this problem of vectorization and local persistence. The next, step is to convert the Textual document to Vectorised documents which can be loaded into memory. Either use OpenAIEmbeddings to generate the vector. For large documents, you would need a paid account with OpenAI. But this would be faster as it would use OpenAI infrastructure. Another way would be to use HuggingFaceEmbeddings this would be a slower process. In this post, we would stick to OpenAIEmbeddings.
search_index = FAISS.from_documents(source_chunks,embedding=OpenAIEmbeddings())
FAISS and Similarity Search
OpenAI has limitations on the number of tokens you can pass in the context prompt. You can also chain external sources of information. But this external information or text can be huge. As a result, may not be directly transferable to OpenAI.
The next step in this process is to first send the user query or questions to the local Vector store(FAISS) and then select top K matching sources to be sent to OpenAI and the source document from which it would be able to generate the response.
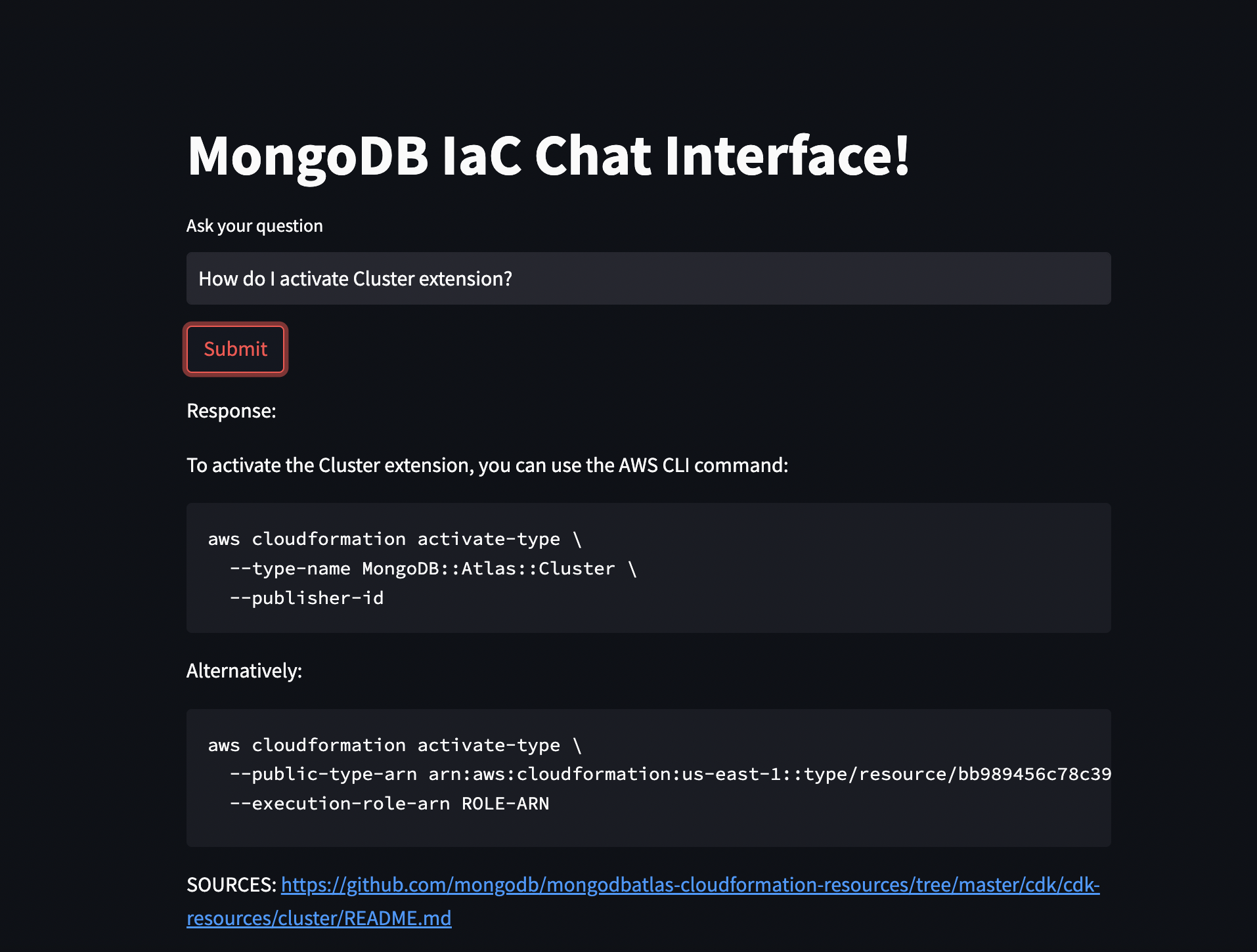
Create an App using Streamlit for the Chatbot
For UI, we sprinkled some Steamlit code. This code consists of a few widgets; one to take user questions, a button to submit the question and another widget to display the response received from the bot.

TO-DO
LangChain also provides a Prompt Template, to help build shareable templates. The template would also be useful to provide the chatbot with a certain persona and also response. Right now, we have not included memory in our application. We would also explore a few other models from HuggingFace to generate embeddings.
Source Code:
https://github.com/SuperMohit/chat-ml



